【教程】:快速入门MongoDB数据库
【教程】:快速入门MongoDB数据库
转载自 https://blog.csdn.net/qq_40558166/article/details/102941708
一、MongoDB的介绍和安装
1.介绍MongoDB
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
总结一下MongoDB的特点
- MongoDB 是一个文档存储的数据库,操作起来比较简单和容易。
- MongoDB安装简单。
- MongoDB支持多种编程语言:PYTHON,JAVA,C++,PHP,C#等多种语言。
- Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
- MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
MongoDB和传统的关系型数据库区别
- 传统数据库特点是存储结构化数据,数据以行为单位,每行的数据结构和类型相同
- MongoDB存储的是文档,每个文档得结构可以不相同
- MongoDB的集合不需要提前创建,可隐式创建,而关系型数据库的表需要提前定义
MongoDB和MySQL中字段的区别
2.安装MongoDB
接下来我们进入安装环节(安装包及可视化包下载地址):
开始安装:
1.指定安装路径
D:\MongoDB\Server\3.4
2.path中配置环境变量
D:\MongoDB\Server\3.4\bin

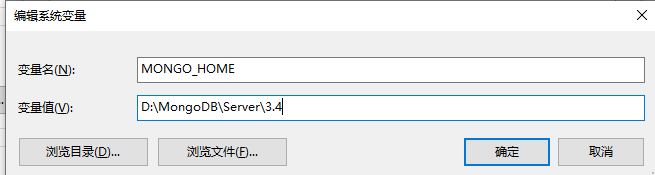
添加环境变量MONGO_HOME
变量名:MONGO_HOME
变量值:D:\MongoDB\Server\3.4
3.创建一个文件存放数据库的文件夹db和一个logs文件夹
D:\MongoDB\Server\3.4\data\db
D:\MongoDB\Server\3.4\data\logs
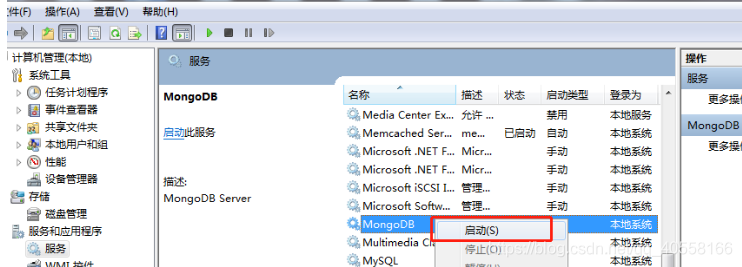
4.将MongoDB配置成一个服务
以管理员方式开启cmd并进入MongoDB的bin文件夹下,输入命令:
d:
cd D:\MongoDB\Server\3.4\bin
再运行配置服务的命令:
mongod --bind_ip 0.0.0.0 --logpath D:\MongoDB\Server\3.4\data\logs\mongo.log --logappend --dbpath D:\MongoDB\Server\3.4\data\db --port 27017 --serviceName "MongoDB" -serviceDisplayName "MongoDB" --install5.启动服务
6.启动
开启服务器:
mongod --dpath 数据存放的文件夹开启客户端:
mongodb://[用户名:密码@]主机地址1[:端口号]
默认不填写为链接本地
例如:使用用户名fred,密码foobar登录localhost的admin数据库
mongodb://fred:foobar@localhost
在这里我们输入以下命令开启
打开cmd,命令行启动
mongod --dbpath D:\MongoDB\Server\3.4\data\db
再打开一个cmd
mongod
二、MongoDB的基本操作命令
1.MongoDB对库的操作
MongoDB 中默认的数据库为 test,如果你没有创建新的数据库,集合将存放在 test 数据库中。
------------------创建数据库(数据库不存在为创建,存在即切换到指定数据库。)
use 库名
------------------查看当前所在的数据库
db
-----------------查看所有数据库(当创建库,但是库中没数据,则库不会被显示,除非插入数据)
show dbs
------------------删除数据库(先使用该库)
use 库名
db.dropDatabase()2.MongoDB对集合的基本操作
进入指定库后,可以对集合(表)进行一些操作
1创建空集合
db.createCollection(集合名字, 可选参数)
可选参数:
- capped(可选,布尔类型):如果为 true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。当该值为 true 时,必须指定 size 参数。
- size(可选,数值):为固定集合指定一个最大值,即字节数。如果 capped 为 true,也需要指定该字段。
- max(可选,数值):指定固定集合中包含文档的最大数量。
2.隐式创建集合
# 直接向不存在的集合插入数据,会自动创建集合
db.集合名字.insert({'name':'张三'})3查看已有集合
show collections
或者
show tables3.4删除集合
db.collection.drop() # 删除成功返回true三、MongoDB对数据的增删改查
1.添加数据
①insertone()插入一条数据
db.集合名.insertone()
# 举例:
db.test.insertone( { item: "card", qty: 15 } );② insertMany()插入多条数据
db.test.insertMany()
# 举例:
db.test.insertMany([
{ item: "card", qty: 15 },
{ item: "envelope", qty: 20 },
{ item: "stamps", qty:30 }
]);③ insert()插入一条或者多条
db.集合名字.insert(数据)
# --------------------------------举例:插入一条数据
db.test.insert( { item : "card", qty : 15 })
db.test.find() # 先查看一下结果
{"_id":Objectlid("5bacac84bb5e8c5dff78dc21"), "item":"cardn, "qty":15 }
# -----------------------------举例:插入多条数据
db.test.insert(
[
{ _id: 11, item: "pencil", qty: 50, type: "no.2" },
{ item: "pen", qty: 20 },
{ item: "eraser", qty: 25 }
]
)
db.test.find()
{ "_id" : 11, "item" : "pencil", "qty" : 50, "type" : "no.2" }
{ "_id" : Objectld("5bacf31728b746e917e06b27"), "item" : "pen", "qty" : 20 }
{ "_id" : Objectld("5bacf31728b746e917e06b28"), "item" : "eraser", "qty" : 25 }注意:
若插入的数据主键已经存在,则会抛
org.springframework.dao.DuplicateKeyException异常,提示主键重复,不保存当前数据。插入多条时候,有序插入命令
> db.test.insert([ {_id:10, item:"pen", price:"20" }, {_id:12, item:"redpen", price: "30" }, {_id:11, item:"bluepen", price: "40" } ], {ordered:true} )在设置
ordered:true时,插入的数据是有序的,如果存在某条待插入文档和集合的某文档 _id 相同的情况,_id 相同的文档与后续文档都将不再插入。在设置ordered:false时,除了出错记录(包括 _id 重复)外其他的记录继续插入。
2.更新数据
update函数参数说明:
db.collection.update(
<query>, # update的查询条件,类似sql update查询内where后面的。
<update>, # update的对象和一些更新的操作符(如$,$inc...)等,可以理解为sql update查询内set后面
{
upsert: <boolean>,# 可选参数,如果不存在update的记录,插入新对象,默认是false,不插入。
multi: <boolean>, # 可选, 默认是false,只更新找到的第一条记录,true为按条件查找并全部更新
writeConcern: <document> # 可选,抛出异常的级别。
}
)2.1 set关键字
添加数据
> db.test2.insert({'name':'张三','age':12})
WriteResult({ "nInserted" : 1 })使用set关键字,修改name为李四
> db.test2.update({'name':'张三'},{$set:{'name':'李四'}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
# 查询该条数据,成功修改
> db.test2.find()
{ "_id" : ObjectId("5f645e811e1dd14f99674e07"), "name" : "李四", "age" : 12 }倘若不加set,修改李四名字为王五
> db.test2.update({'name':'李四'},{'name':'王五'})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })查询所有数据,发现没有{'name':王五','age':12}的数据,只有{'name':王五'},说明不加入set不是修改,而是替换
> db.test2.find()
{ "_id" : ObjectId("5f645e811e1dd14f99674e07"), "name" : "王五" }2.2 unset关键字
添加数据
> db.test2.insert({'name':'张三','age':12})
WriteResult({ "nInserted" : 1 })使用unset关键字,name字段
> db.test2.update({'name':'张三'},{$unset:{'name':'张三'}})
# 查询该数据,成功删除name字段
> db.test2.find()
{ "_id" : ObjectId("5f6460e41e1dd14f99674e08"), "age" : 12 }2.3 rename关键字
原始数据
> db.test2.find()
{ "_id" : ObjectId("5f6460e41e1dd14f99674e08"), "age" : 12 }使用rename,将age字段修改为num
> db.test2.update({'age':12},{$rename:{'age':'num'}})
# 成功修改字段
> db.test2.find()
{ "_id" : ObjectId("5f6460e41e1dd14f99674e08"), "num" : 12 }2.4 inc关键字
原始数据
> db.test2.find()
{ "_id" : ObjectId("5f6460e41e1dd14f99674e08"), "num" : 12 }使用inc关键字,可以增加一个字段
> db.test2.update({'num':12},{$inc:{'sex':1}})
# 成功添加字段
> db.test2.find()
{ "_id" : ObjectId("5f6460e41e1dd14f99674e08"), "num" : 12, "sex" : 1 }2.5 其他可选参数
multi修改多条,修改name为张三的所有人的年龄为21
db.user.update({'name':'张三'},{$set:{'age': 21}},{multi:true})upsert查询到数据则修改,查询不到则将数据添加,但是注意查询条件不会被添加到数据字段
db.stu.update({'name':'zs'},{$set:{'name':'ls'}},{upsert:true});
# 如果name为zs的数据不存在,则会自动添加一条{'name':'ls'}的数据3.查询数据
基本函数
db.集合名.find(查询条件)
# 将查询的数据格式化展示
db.集合名.find(查询条件).pretty()3.1 条件操作符语法
| 操作 | 格式 | 范例 | sql中的类似语句 |
|---|---|---|---|
| = | {<key>:<value>} | db.col.find({"by":"菜鸟教程"}).pretty() | where by = '菜鸟教程' |
| < | {<key>:{$lt:<value>}} | db.col.find({"likes":{$lt:50}}).pretty() | where likes < 50 |
| <= | {<key>:{$lte:<value>}} | db.col.find({"likes":{$lte:50}}).pretty() | where likes <= 50 |
| > | {<key>:{$gt:<value>}} | db.col.find({"likes":{$gt:50}}).pretty() | where likes > 50 |
| >= | {<key>:{$gte:<value>}} | db.col.find({"likes":{$gte:50}}).pretty() | where likes >= 50 |
| != | {<key>:{$ne:<value>}} | db.col.find({"likes":{$ne:50}}).pretty() | where likes != 50 |
3.2 逻辑查询语法
and语法:符合多个条件
db.集合名.find({查询条件1},{查询条件2},{查询条件3}...)
或者
db.集合名.find({$and:[{查询条件1},{查询条件2}]})or语法:符合条件1或符合条件2
db.集合名.find({$or:[{查询条件1},{查询条件2}]})
nin语法:不符合数值1或数值2的
db.集合名.find({字段名:{$nin:[值1,值2,值3...]}})3.3 查询示例
| 要求 | 代码 |
|---|---|
| 查看所有 | db.stu.find() |
| 查看name=zs | db.stu.find({'name':'zs'}) |
| 查看name!=zs的 | db.stu.find({'name':{$ne:'zs'}}) |
| 查看name=zs并且age=12 | db.stu.find({'name':'zs'},{'age':12}) |
| 年龄不在15,16,17的都显示 | db.stu.find({'age':{$nin:[15,16,17]}}) |
| 年龄在15,16,17的都显示 | db.stu.find({'age':{$in:[15,16,17]}}) |
| 存在age字段的都显示 | db.stu.find({'age':{$exists:1}}) |
| 不存在age字段的都显示 | db.stu.find({'age':{$exists:0}}) |
| 查询年龄=30岁的数据 | db.stu.find({age:30}) |
| 查询年龄>30岁的数据 | db.stu.find({age:{$gt:30}}) |
| 查询年龄>=30岁的数据 | db.stu.find({age:{$gte:30}}) |
| 查询年龄<30岁的数据 | db.stu.find({age:{$lt:30}}) |
| 查询年龄<=30岁的数据 | db.stu.find({age:{$lte:30}}) |
| 查询10岁的男孩或者20岁的女孩 | db.stu.find({KaTeX parse error: Expected '}', got 'EOF' at end of input: or:[{and:[{'age':10},{'sex':'男'}]},{$and:[{'age':20},{'sex':'女'}}]}) |
4.删除数据
函数参数说明:
先查询,后删除
db.collection.remove(
<query>, # (可选)删除的文档的条件。
{
justOne: <boolean>,#(可选)如果为true/1,则只删除一个文档,用默认值false,删除所有匹配条件数据
writeConcern: <document> #可选)抛出异常的级别。
}
)删除举例
| 要求 | 代码 |
|---|---|
| 删除年龄等于30岁的数据 | db.stu.remove({age:30}) |
| 删除年龄大于30岁的数据 | db.stu.remove({age:{$gt:30}}) |
| 删除年龄大于等于30岁的数据 | db.stu.remove({age:{$gte:30}}) |
| 删除年龄小于30岁的数据 | db.stu.remove({age:{$lt:30}}) |
| 删除年龄不等于30岁的数据 | db.stu.remove({age:{$ne:30}}) |
四、MongoDB中的一些常用方法
| 方法 | 说明 | 代码 |
|---|---|---|
| 计数方法count() | 输出符合查询条件的数据个数 | df.集合名.find().count() |
| 限制输出数量limit() | 可以限制符合查询条件的数据的输出数量最多为number个 | db.集合名.find().limit(NUMBER) |
| 跳过指定数量skip() | 配合limit()方法使用,可以跳过num1条数据,然后查看num2条数据 | db.集合名.find().limit(NUM2).skip(NUM1) |
| 排序方法sort() | 在 MongoDB 中使用 sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。 | db.集合名.find().sort({KEY:1}) |
| 创建索引createIndex() | 索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。 | db.集合名.createIndex(keys, options) Key 值为要创建的索引字段,1 为指定按升序创建索引,降序创建索引指定为 -1 即可。 举例:db.col.createIndex({"title":1,"description":-1}) |
五、MongoDB 聚合函数
函数说明: MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)。
语法:
db.COLLECTION_NAME.aggregate([
{管道1},
{管道2},
{管道3},
...
])MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理,管道操作是可以重复的。
1.聚合框架中常用的几个管道操作
- ①match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
- ② group:将集合中的文档分组,可用于统计结果。
- ③project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
- ④limit:用来限制MongoDB聚合管道返回的文档数。
- ⑤skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- ⑥sort:将输入文档排序后输出。
group中的一下操作表达式:
| 表达式 | 描述 |
|---|---|
| $sum | 计算总和。 |
| $avg | 计算平均值 |
| $min | 获取集合中所有文档对应值得最小值。 |
| $max | 获取集合中所有文档对应值得最大值。 |
| $first | 根据资源文档的排序获取第一个文档数据 |
| $last | 根据资源文档的排序获取最后一个文档数据 |
2.聚合操作练习
1.查询每个栏目下的商品数量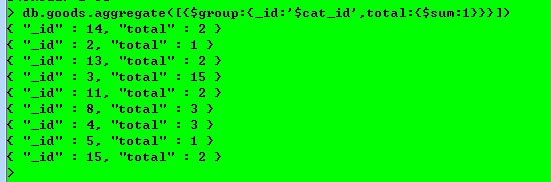
2.查询goods下有多少条商品

3.查询每个栏目下价格大于50元的商品个数(先筛选大于50的,再分组)
db.goods.aggregate([{$match:{shop_price:{$gt:50}}}, {$group:{_id:"$cat_id",total:{$sum:1}}}])
4.查询每个栏目下的库存量
db.goods.aggregate([{$group:{_id:"$cat_id" , total:{$sum:"$goods_number"}}}])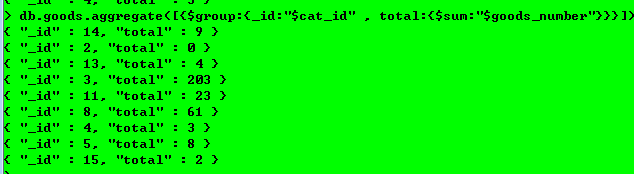
5.查询每个栏目下 价格大于50元的商品个数 #并筛选出"满足条件的商品个数" 大于等于3的栏目
(1)价格大于50:
{$match:{shop_price:{$gt:50}}}
(2)要想查出个数大于3的栏目,必须先对cat_id进行分组:
{$group:{_id:"$cat_id",total:{$sum:1}}}
(3)最后用match来去除大于3个的栏目
{$match:{total:{$gte:3}}}
6.查询每个栏目下的库存量,并按库存量排序
思路:
(1)按栏目的库存量分组(2)排序
{$group:{_id:"$cat_id" , total:{$sum:"$goods_number"}}}
{$sort:{total:1}}
db.goods.aggregate([{$group:{_id:"$cat_id" , total:{$sum:"$goods_number"}}}, {$sort:{total:1}}])
1是正序,-1是逆序
六、游标
MongoDB在底层上时用JS代码实现的,因此使用JS代码在数据库中插入1000条数据。
for (var i=0;i<1000;i++){
db.bar.insert({_id:i+1,title:'hello world'+i,content:'aaa'+i})
}
#查询数据
db.bar.find()问题:如果我们想将结果一个一个展示,类似python的生成器,在MongoDB中这样实现叫做游标。
1、游标是什么?
通俗的说游标不是查询结果,而是查询的返回资源或者接口,就像python中的生成器,通过这个生成器,可以一次一次的获取每一个资源。
2、游标的声明:
var curor_name = db.bar.find()3、游标的操作:
curor.hasNext()//判断游标是否已经取到尽头
curor.next()//取出游标的下一个单元例如:
var mycusor = db.bar.find().limit(5)
print(mycusor.next())//会显示是一个bson格式的数据
printjson(mycusor.next())我们可以写一个while循环来打印游标结果:
while(mycusor.hasNext()){
printjson(mycusor.next())
}游标还有一个toArray()方法,方便我们可以看到所有行
print(mycusor.toArray())//看到所有行
print(mycusor.toArray()[2])//看到第二行注意不要使用toArray(),原因是会把所有的行立即以对象的形式放在内存中,可以再取出少数几行时,使用此功能。
4、cursor.forEach(回调函数)
var gettile = function(obj){print(obj.goods_name)}
var cursor = db.goods.find()
cursor.forEach(gettile)5、游标在分页中的应用
var mycusor = db.bar.find().skip(90).limit(10)//跳过90条,取10条。则是查询结果中,跳过前9995行
var mycursor = db.bar.find().skip(9995);查询第901页,每页10条
则是 var mytcursor = db.bar.find().skip(9000).limit(10);七、MongoDB的导入导出
1.通用选项
| 选项 | 意义 |
|---|---|
| -h | 主机 |
| --port | 端口 |
| -u | 用户名 |
| -p | 密码 |
| -d | 库名 |
| -c | 集合名 /表名 |
| -f field1,field2... | 字段名/列名 |
| -q | 查询条件 |
| -o | 导出的文件名 |
| -- csv | 导出csv格式(便于和传统数据库交换数据) |
| --type | csv/json(默认) |
| --file | 备份文件路径 |
2.导出文件
默认导出json格式:
mongoexport -d 库名 -c 表名 -o 导出的文件名.json --type json
# 默认也是json类型
mongoexport -d 库名 -c 表名 -o 导出的文件名.json导出csv文件(必须指定导出的列,不加type变为json类型)
mongoexport -d 库名 -c 表名 -o 导出的文件名.csv --type csv -f 导出列1,导出列2...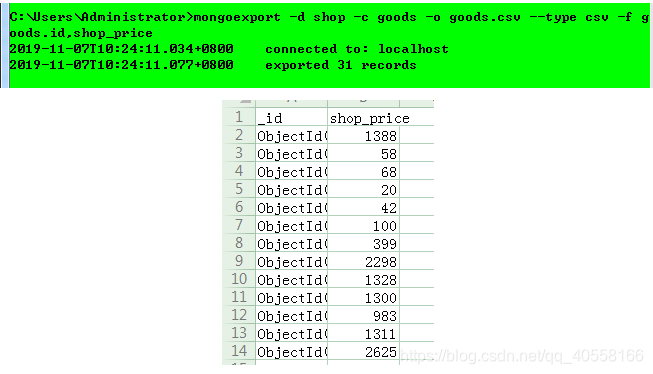
3.导入文件
导入json格式:
mongoimport -d 库名 -c 表名(没有自动创建) --file 导入的json文件名导入csv格式
mongoimport -d 库名 -c 表名 --type csv -f 列1,列2 --file 导入的csv文件名4.二进制bson文件的导入和导出
①mongodump 导出二进制bson结构的数据及其索引信息
mongodum -d 库名 -c 表名注意:
- 默认是导出到mongo下的dump目录,导出的文件放在以database命名的目录下
- 每个表导出2个文件,分别是bson结构的数据文件, json的索引信息
- 如果不声明表名, 导出所有的表
②mongorestore 导入二进制文件
mongorestore -d shop -c goods --dir ./dump/shop/goods.bson
优点:二进制备份,不仅可以备份数据,还可以备份索引,备份数据比较小.速度比较快。
八、Python操作MongoDB
安装mongo模块
pip install pymongo
举例:
import pymongo
# 1.创建连接
client = pymongo.MongoClient('mongodb://127.0.0.1:27017/')
# 2.连接数据库
db = client['shop']
# 3.写语句,获取游标
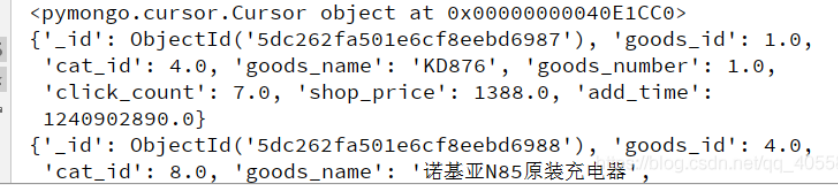
result = db['goods'].find() # 游标对象
for i in result:
print(i)