05-Bean的生命周期(上)
05-Bean的生命周期(上)
Spring最重要的功能就是帮助程序员创建对象(也就是IOC),而启动Spring就是为创建Bean对象做准备,所以我们先明白Spring到底是怎么去创建Bean的,也就是先弄明白Bean的生命周期。
Bean的生命周期就是指:在Spring中,一个Bean是如何生成的,如何销毁的
Bean生命周期流程图:
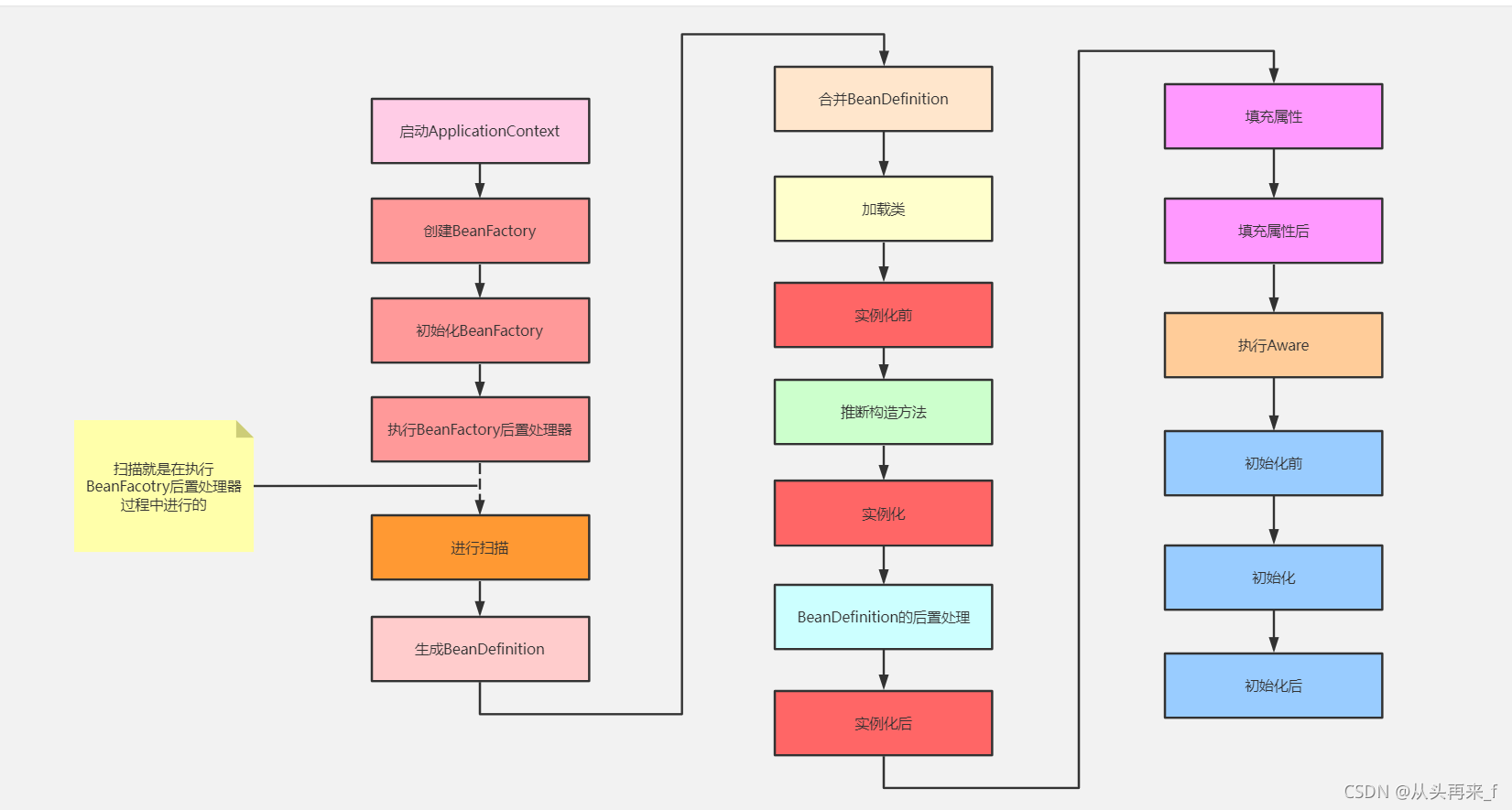
引言
首先你要明白一点,Spring Bean总体的创建过程如下:
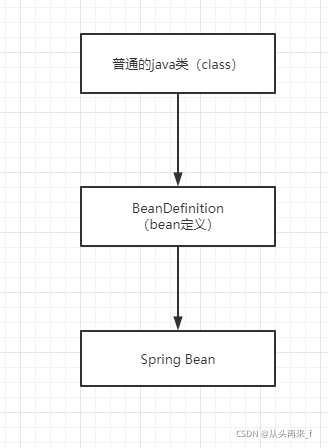
以注解类变成Spring Bean为例,Spring会扫描指定包下面的Java类,然后将其变成beanDefinition对象,然后Spring会根据beanDefinition来创建bean ,特别要记住一点,Spring是根据beanDefinition来创建Spring bean的,为什么不直接使用对象的class对象来创建bean呢?因为在class对象仅仅能描述一个对象的创建,它不足以用来描述一个Spring bean,而对于是否为懒加载、是否是首要的、初始化方法是哪个、销毁方法是哪个,这个Spring中特有的属性在class对象中并没有,所有Spring就定义了beanDefinition来完成bean的创建。
关于beanDefinition之前的文章有Spring源码学习(三)-- 底层架构核心概念解析_学习笔记-CSDN博客。
先看下最基本的启动 Spring 容器的例子:
public static void main(String[] args) {
//加载spring上下文
ApplicationContext context=new AnnotationConfigApplicationContext(MyConfig.class);
Car bean = context.getBean(Car.class);
System.out.println(bean);
}以上代码就可以利用配置文件来启动一个 Spring 容器了。
我们看一下AnnotationConfigApplicationContext的构造方法
public AnnotationConfigApplicationContext(Class<?>... componentClasses) {
//调用无参构造函数,会先调用父类GenericApplicationContext的构造函数
//父类的构造函数里面就是初始化DefaultListableBeanFactory,并且赋值给beanFactory
//本类的构造函数里面,初始化了一个读取器:AnnotatedBeanDefinitionReader read,一个扫描器ClassPathBeanDefinitionScanner scanner
//scanner的用处不是很大,它仅仅是在我们外部手动调用 .scan 等方法才有用,常规方式是不会用到scanner对象的
this();
//把传入的类进行注册,这里有两个情况,
//传入传统的配置类
//传入bean(虽然一般没有人会这么做
//看到后面会知道spring把传统的带上@Configuration的配置类称之为FULL配置类,不带@Configuration的称之为Lite配置类
//但是我们这里先把带上@Configuration的配置类称之为传统配置类,不带的称之为普通bean
register(componentClasses);
//刷新
refresh();
}首先会调用AnnotationConfigApplicationContext的无参构造方法:
public AnnotationConfigApplicationContext() {
//会隐式调用父类的构造方法,初始化DefaultListableBeanFactory
//初始化一个Bean读取器
this.reader = new AnnotatedBeanDefinitionReader(this);
//初始化一个扫描器,它仅仅是在我们外部手动调用 .scan 等方法才有用,常规方式是不会用到scanner对象的
this.scanner = new ClassPathBeanDefinitionScanner(this);
}首先会隐式调用父类的构造方法,初始化DefaultListableBeanFactory,为之后创建bean使用
然后初始化一个bean定义读取器,this.reader = new AnnotatedBeanDefinitionReader(this);这一步其实做了很多事情,注册了几个spring内置的bean(BeanFactoryPostProcessor和BeanPostProcessor)具体的之后会在启动流程分析的文章分析
再然后初始化了一个扫描器,无参构造方法到此结束。
接下来是注册配置类(register(componentClasses);),简单来说就是把我们自定义的javaconfig解析为BeanDefinition,同样具体的会在之后文职分析
最后是spring最重要的方法了,IOC容器刷新(refresh())
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
StartupStep contextRefresh = this.applicationStartup.start("spring.context.refresh");
// Prepare this context for refreshing.
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
// 准备BeanFactory
// 1. 设置BeanFactory的类加载器、表达式解析器、类型转化注册器
// 2. 添加三个BeanPostProcessor,注意是具体的BeanPostProcessor实例对象
// 3. 记录ignoreDependencyInterface
// 4. 记录ResolvableDependency
// 5. 添加三个单例Bean
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
// 子类来设置一下BeanFactory
postProcessBeanFactory(beanFactory);
StartupStep beanPostProcess = this.applicationStartup.start("spring.context.beans.post-process");
// Invoke factory processors registered as beans in the context.
// BeanFactory准备好了之后,执行BeanFactoryPostProcessor,开始对BeanFactory进行处理
// 默认情况下:
// 此时beanFactory的beanDefinitionMap中有6个BeanDefinition,5个基础BeanDefinition+AppConfig的BeanDefinition
// 而这6个中只有一个BeanFactoryPostProcessor:ConfigurationClassPostProcessor
// 这里会执行ConfigurationClassPostProcessor进行@Component的扫描,扫描得到BeanDefinition,并注册到beanFactory中
// 注意:扫描的过程中可能又会扫描出其他的BeanFactoryPostProcessor,那么这些BeanFactoryPostProcessor也得在这一步执行
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
// 将扫描到的BeanPostProcessors实例化并排序,并添加到BeanFactory的beanPostProcessors属性中去
registerBeanPostProcessors(beanFactory);
beanPostProcess.end();
// Initialize message source for this context.
// 设置ApplicationContext的MessageSource,要么是用户设置的,要么是DelegatingMessageSource
initMessageSource();
// Initialize event multicaster for this context.
// 设置ApplicationContext的applicationEventMulticaster,么是用户设置的,要么是SimpleApplicationEventMulticaster
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
// 给子类的模板方法
onRefresh();
// Check for listener beans and register them.
// 把定义的ApplicationListener的Bean对象,设置到ApplicationContext中去,并执行在此之前所发布的事件
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
resetCommonCaches();
contextRefresh.end();
}
}
}有关Spring Bean生命周期最主要的方法有三个invokeBeanFactoryPostProcessors 、registerBeanPostProcessors 和finishBeanFactoryInitialization。
其中invokeBeanFactoryPostProcessors方法会执行BeanFactoryPostProcessors后置处理器及其子接口BeanDefinitionRegistryPostProcessor,执行顺序先是执行BeanDefinitionRegistryPostProcessor接口的postProcessBeanDefinitionRegistry方法,然后执行BeanFactoryPostProcessor接口的postProcessBeanFactory方法。
对于BeanDefinitionRegistryPostProcessor接口的postProcessBeanDefinitionRegistry方法,该步骤会扫描到指定包下面的标有注解的类,然后将其变成BeanDefinition对象,然后放到一个Spring中的Map中,用于下面创建Spring bean的时候使用这个BeanDefinition
其中registerBeanPostProcessors方法 根据实现了PriorityOrdered、Ordered接口,排序后注册所有的BeanPostProcessor后置处理器,主要用于Spring Bean创建时,执行这些后置处理器的方法,这也是Spring中提供的扩展点,让我们能够插手Spring bean创建过程。
finishBeanFactoryInitialization是完成非懒加载的Spring bean的创建的工作。
上面说到了spring生成bean的最主要两步:**扫描(生成BeanDefinition)---创建非懒加载单例bean,**以下将会从这两方面的源码进行具体分析,当然在refresh方法中还有很多方法,会在创建bean之前做很多准备工作,这些之后会在启动流程的文章去分析。
Bean的生成过程
1. 生成BeanDefinition
Spring启动的时候会进行扫描,会先调用org.springframework.context.annotation.ClassPathBeanDefinitionScanner#doScan(String... basePackages)扫描某个包路径,并得到BeanDefinition的Set集合。
上面说到的AnnotationConfigApplicationContext的无参构造方法中会初始化一个扫描器就是这个ClassPathBeanDefinitionScanner,实际上在扫描时是重新实例化了一个扫描器。
扫描是在refresh中的invokeBeanFactoryPostProcessors方法中执行的,有一个spring内置的BeanFactoryPostProcessors(ConfigurationClassPostProcessor),具体的入口会放在之后的启动流程中去说,这里先说一下spring扫描的底层实现
Spring扫描底层流程:
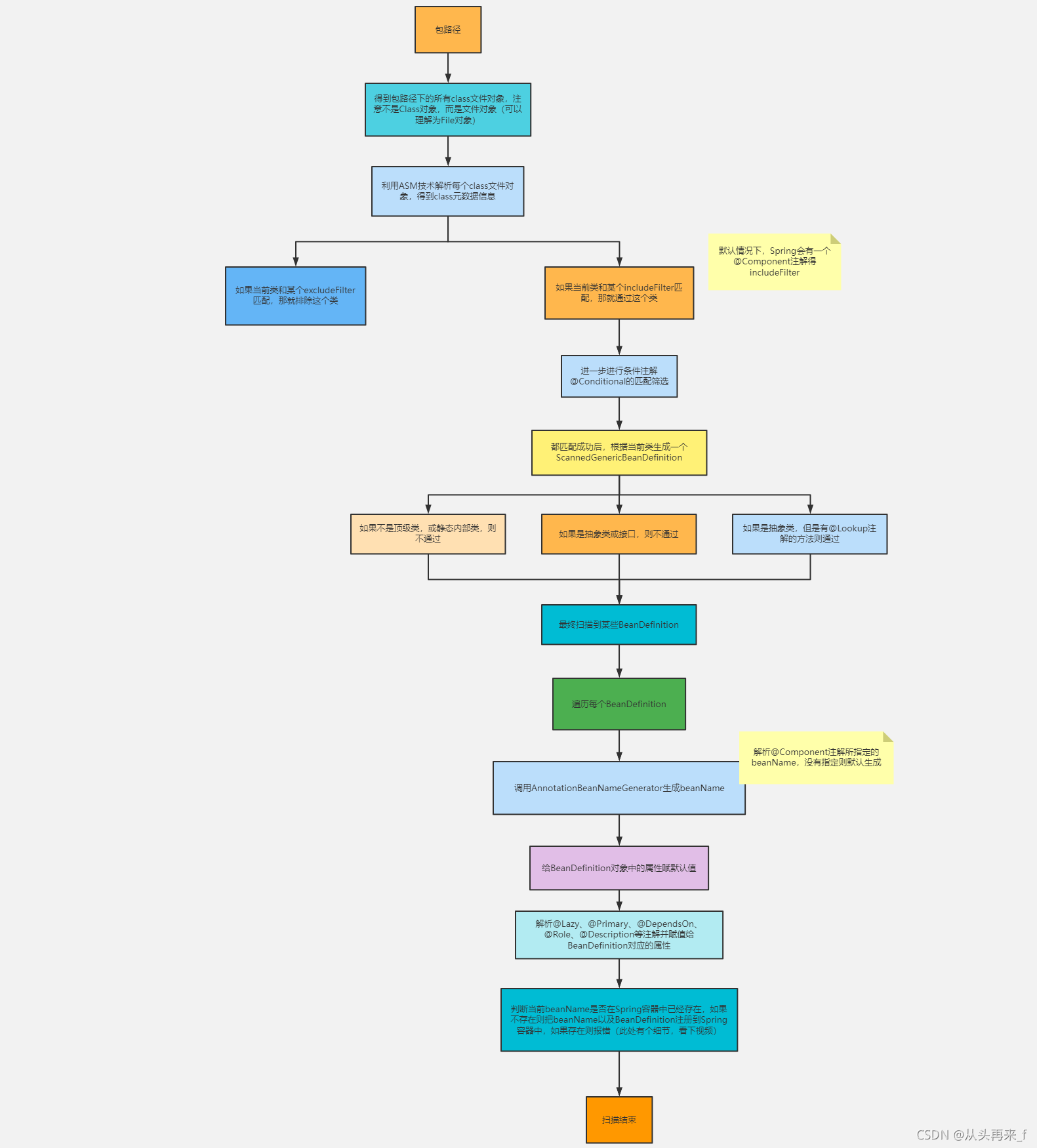
接下来,我们看代码:
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
//创建bean定义的holder对象用于保存扫描后生成的bean定义对象
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
//循环我们的包路径集合
for (String basePackage : basePackages) {
//找到候选的Components
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
//获取我们的beanName
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
//这是默认配置 autowire-candidate
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
// 解析@Lazy、@Primary、@DependsOn、@Role、@Description
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
//把我们解析出来的组件bean定义注册到我们的IOC容器中(容器中没有才注册)
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}因为传进来的包路径可能是数组,会循环包路径
可以看到
这一行代码是关键,根据包路径解析到了bean定义的set集合
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
//spring支持component索引技术,需要引入一个组件,因为大部分情况不会引入这个组件
//所以不会进入到这个if
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
return scanCandidateComponents(basePackage);
}
}Spring支持component索引技术,需要引入一个组件,大部分项目没有引入这个组件,所以会进入scanCandidateComponents方法:
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
//把我们的包路径转为资源路径 com/fztx/**/*.class
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
//扫描指定包路径下面的所有.class文件
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
//循环我们的resources集合
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
try {
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
//是不是候选的组件--excludeFilters、includeFilters判断
if (isCandidateComponent(metadataReader)) {
//包装成为一个ScannedGenericBeanDefinition
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
//加入到集合中
candidates.add(sbd);
}
else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + resource);
}
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not matching any filter: " + resource);
}
}
}
catch (FileNotFoundException ex) {
if (traceEnabled) {
logger.trace("Ignored non-readable " + resource + ": " + ex.getMessage());
}
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to read candidate component class: " + resource, ex);
}
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
}- 把传进来的类似命名空间形式的字符串转换成类似类文件地址的形式,然后在前面加上classpath,即:com.xx=>classpath:com/xx/**/*.class。

2.通过ResourcePatternResolver获得指定包路径下的所有.class文件(Spring源码中将此文件包装成了Resource对象)
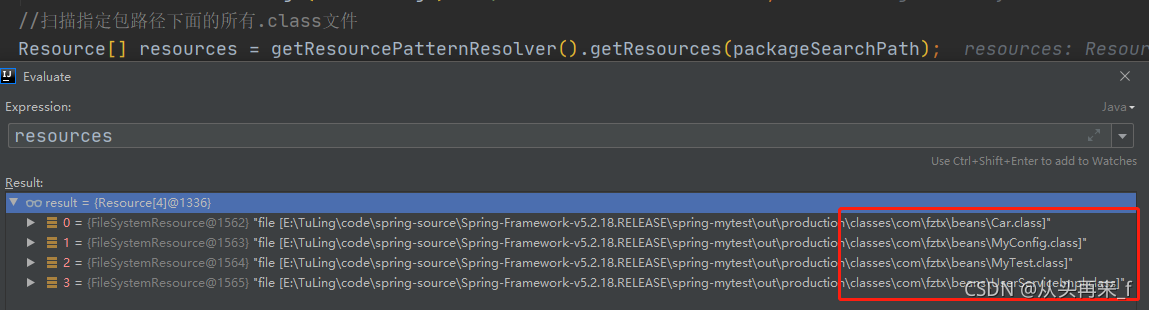
3.遍历每个Resource对象
4.利用MetadataReaderFactory解析Resource对象得到MetadataReader(在Spring源码中MetadataReaderFactory具体的实现类为CachingMetadataReaderFactory,MetadataReader的具体实现类为SimpleMetadataReader)
Spring源码学习(三)-- 底层架构核心概念解析_学习笔记-CSDN博客有关于MetadataReader的介绍


5.利用MetadataReader进行excludeFilters和includeFilters,以及条件注解@Conditional的筛选(条件注解:某个类上是否存在@Conditional注解,如果存在则调用注解中所指定的类的match方法进行匹配,匹配成功则通过筛选,匹配失败则pass掉。)
protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {
for (TypeFilter tf : this.excludeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return false;
}
}
// 符合includeFilters的会进行条件匹配,通过了才是Bean,也就是先看有没有@Component,再看是否符合@Conditional
for (TypeFilter tf : this.includeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return isConditionMatch(metadataReader);
}
}
return false;
}首先进行排除过滤器匹配,如果有一个排除过滤器匹配,则返回false
再进行包含过滤器匹配,spring默认注册了一个@Component的包含过滤器(在创建ClassPathBeanDefinitionScanner扫描器时)

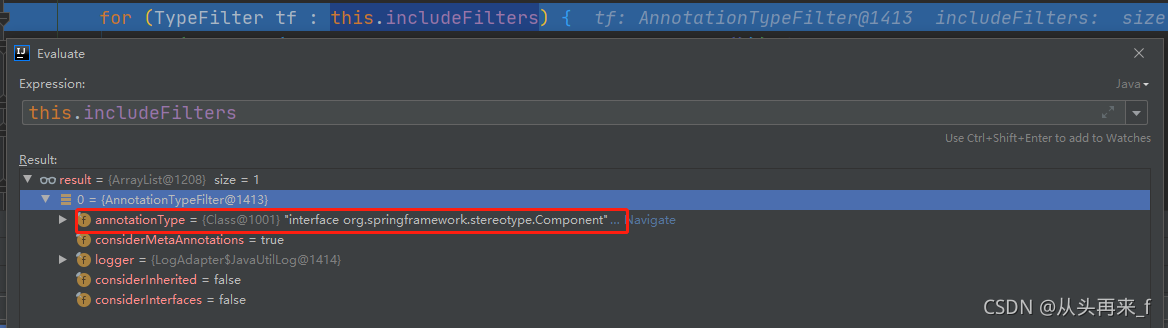
如果和包含过滤器中的任何一个条件匹配,那么就有可能成为一个bean,就会继续进行条件匹配

就是@Conditional注解的条件匹配
6.筛选通过后,基于metadataReader生成ScannedGenericBeanDefinition

public ScannedGenericBeanDefinition(MetadataReader metadataReader) {
Assert.notNull(metadataReader, "MetadataReader must not be null");
this.metadata = metadataReader.getAnnotationMetadata();
setBeanClassName(this.metadata.getClassName());
setResource(metadataReader.getResource());
}只是把类的名字赋值给 BeanDefinition的beanClass
7.再基于metadataReader判断是不是独立的类(顶级类或者静态内部类)是不是接口或抽象类
protected boolean isCandidateComponent(AnnotatedBeanDefinition beanDefinition) {
AnnotationMetadata metadata = beanDefinition.getMetadata();
return (metadata.isIndependent() && (metadata.isConcrete() ||
(metadata.isAbstract() && metadata.hasAnnotatedMethods(Lookup.class.getName()))));
}metadata.isIndependent() 是一个独立的类(顶级类或者静态内部类)
metadata.isConcrete() 不是接口和抽象类
metadata.isAbstract() && metadata.hasAnnotatedMethods(Lookup.class.getName())
是抽象类但是有被@Lookup注解的方法
8.如果筛选通过,那么就表示扫描到了一个Bean,将ScannedGenericBeanDefinition加入结果集
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
//获取我们的beanName
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
//这是默认配置 autowire-candidate
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
// 解析@Lazy、@Primary、@DependsOn、@Role、@Description
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
//把我们解析出来的组件bean定义注册到我们的IOC容器中(容器中没有才注册)
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}循环筛选通过的BeanDefinition
1.根据BeanDefinition获取beanName,首先解析@Component注解的value值,有值就返回beanName,没有就生成默认的beanName

2.设置BeanDefinition的默认值

protected void postProcessBeanDefinition(AbstractBeanDefinition beanDefinition, String beanName) {
//设置BeanDefinition的默认值
beanDefinition.applyDefaults(this.beanDefinitionDefaults);
//AutowireCondidate表示某个Bean能否被用来做依赖注入
if (this.autowireCandidatePatterns != null) {
beanDefinition.setAutowireCandidate(PatternMatchUtils.simpleMatch(this.autowireCandidatePatterns, beanName));
}
}3.解析@Lazy、@Primary、@DependsOn、@Role、@Description等注解并设置到BeanDefinition

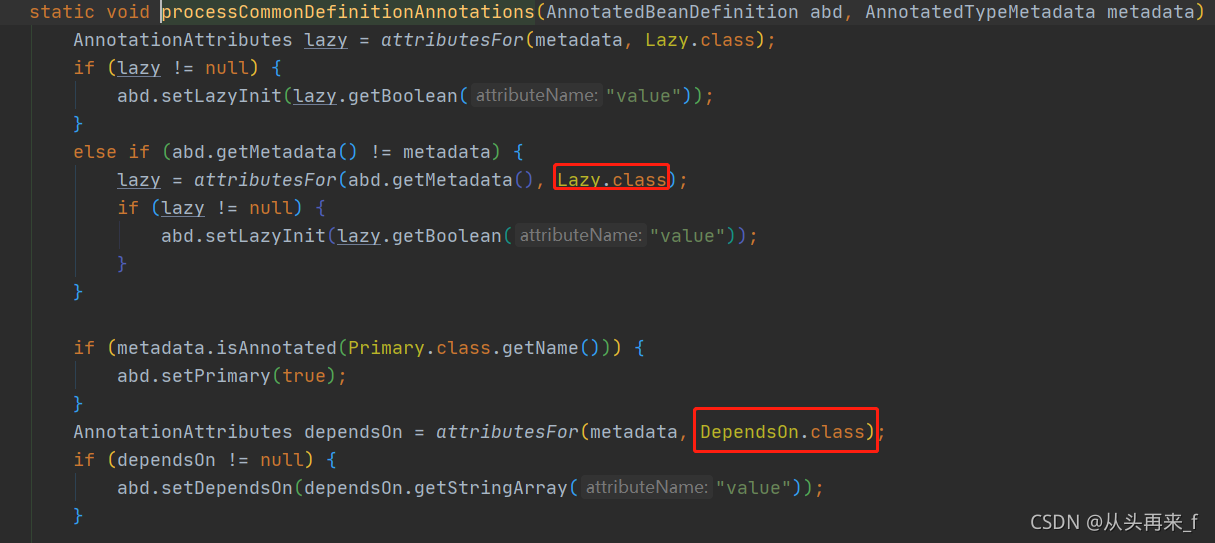
4.检查spring容器中是否已经存在该beanName,没有才会去注册到IOC容器(也就是放到beanDefinitionMap中)
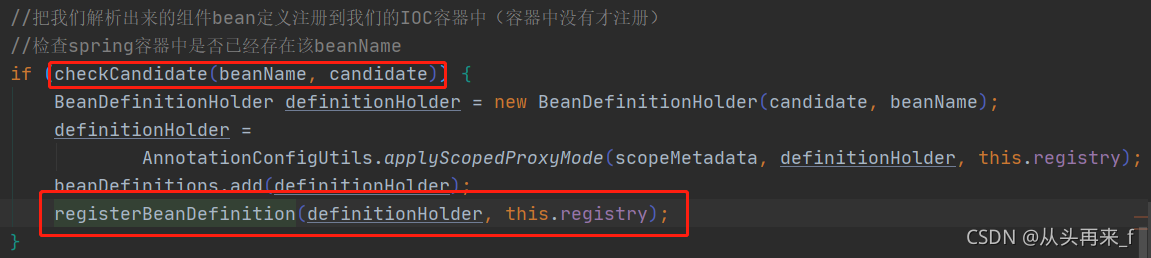

MetadataReader表示类的元数据读取器,主要包含了一个AnnotationMetadata,功能有
- 获取类的名字、
- 获取父类的名字
- 获取所实现的所有接口名
- 获取所有内部类的名字
- 判断是不是抽象类
- 判断是不是接口
- 判断是不是一个注解
- 获取拥有某个注解的方法集合
- 获取类上添加的所有注解信息
- 获取类上添加的所有注解类型集合
值得注意的是,CachingMetadataReaderFactory解析某个.class文件得到MetadataReader对象是利用的ASM 技术,并没有加载这个类到JVM。并且,最终得到的ScannedGenericBeanDefinition对象,beanClass属性存储的是当前类的名字,而不是class对象。(beanClass属性的类型是Object,它即可以存储类的名字,也可以存储class对象)
最后,上面是说的通过扫描得到BeanDefinition对象,我们还可以通过直接定义BeanDefinition,或解析spring.xml文件的<bean/>,或者@Bean注解得到BeanDefinition对象。(后续会分析@Bean注解是怎么生成BeanDefinition的)。
以上通过扫描得到了BeanDefinition,也就是将java---BeanDefinition,按照我们的理解就是要将**beanDefinition对象 -> Spring中的bean,**中间的其他方法之后再看,接下来就是
finishBeanFactoryInitialization方法,创建非懒加载单例bean
我们进入finishBeanFactoryInitialization这方法,里面有一个beanFactory.preInstantiateSingletons()方法:
// Instantiate all remaining (non-lazy-init) singletons.
// 实例化非懒加载的单例Bean
beanFactory.preInstantiateSingletons();@Override
public void preInstantiateSingletons() throws BeansException {
if (logger.isTraceEnabled()) {
logger.trace("Pre-instantiating singletons in " + this);
}
// Iterate over a copy to allow for init methods which in turn register new bean definitions.
// While this may not be part of the regular factory bootstrap, it does otherwise work fine.
List<String> beanNames = new ArrayList<>(this.beanDefinitionNames);
// Trigger initialization of all non-lazy singleton beans...
for (String beanName : beanNames) {
// 获取合并后的BeanDefinition
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
//是否单例懒加载
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {
//是不是FactoryBean
if (isFactoryBean(beanName)) {
// 获取FactoryBean对象
Object bean = getBean(FACTORY_BEAN_PREFIX + beanName);
if (bean instanceof FactoryBean) {
FactoryBean<?> factory = (FactoryBean<?>) bean;
boolean isEagerInit;
if (System.getSecurityManager() != null && factory instanceof SmartFactoryBean) {
isEagerInit = AccessController.doPrivileged(
(PrivilegedAction<Boolean>) ((SmartFactoryBean<?>) factory)::isEagerInit,
getAccessControlContext());
}
else {
isEagerInit = (factory instanceof SmartFactoryBean &&
((SmartFactoryBean<?>) factory).isEagerInit());
}
if (isEagerInit) {
// 创建真正的Bean对象(getObject()返回的对象)
getBean(beanName);
}
}
}
else {
// 创建Bean对象
getBean(beanName);
}
}
}
// 所有的非懒加载单例Bean都创建完了后
// Trigger post-initialization callback for all applicable beans...
for (String beanName : beanNames) {
Object singletonInstance = getSingleton(beanName);
if (singletonInstance instanceof SmartInitializingSingleton) {
SmartInitializingSingleton smartSingleton = (SmartInitializingSingleton) singletonInstance;
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
smartSingleton.afterSingletonsInstantiated();
return null;
}, getAccessControlContext());
}
else {
smartSingleton.afterSingletonsInstantiated();
}
}
}
}注册BeanDefinition时将beanName存到了集合中,现在拿到集合循环创建bean,接下来就看循环例是如何一步一步得到spring bean的。
2. 合并BeanDefinition
通过扫描得到所有BeanDefinition之后,就可以根据BeanDefinition创建Bean对象了,但是在Spring中支持父子BeanDefinition,和Java父子类类似,但是完全不是一回事。
父子BeanDefinition实际用的比较少,使用是这样的,比如:
<bean id="parent" class="com.zhouyu.service.Parent" scope="prototype"/>
<bean id="child" class="com.zhouyu.service.Child"/>这么定义的情况下,child是单例Bean。
<bean id="parent" class="com.zhouyu.service.Parent" scope="prototype"/>
<bean id="child" class="com.zhouyu.service.Child" parent="parent"/>但是这么定义的情况下,child就是原型Bean了。
因为child的父BeanDefinition是parent,所以会继承parent上所定义的scope属性。
而在根据child来生成Bean对象之前,需要进行BeanDefinition的合并,得到完整的child的BeanDefinition。

原有的BeanDefinition是不动的,合并的RootBeanDefinition是新生成的,子BeanDefinition有的属性会覆盖父BeanDefinition的属性。
获取到合并后的BeanDefinition后,首先判断BeanDefinition是不是抽象的(注意这里不是判断类是不是抽象类,因为抽象类是不会生成BeanDefinition,@Lookup注解方法除外),以及判断是不是单例和懒加载

只有非懒加载单例bean才会去创建,之后就是去创建非懒加载单例bean。
代码继续走: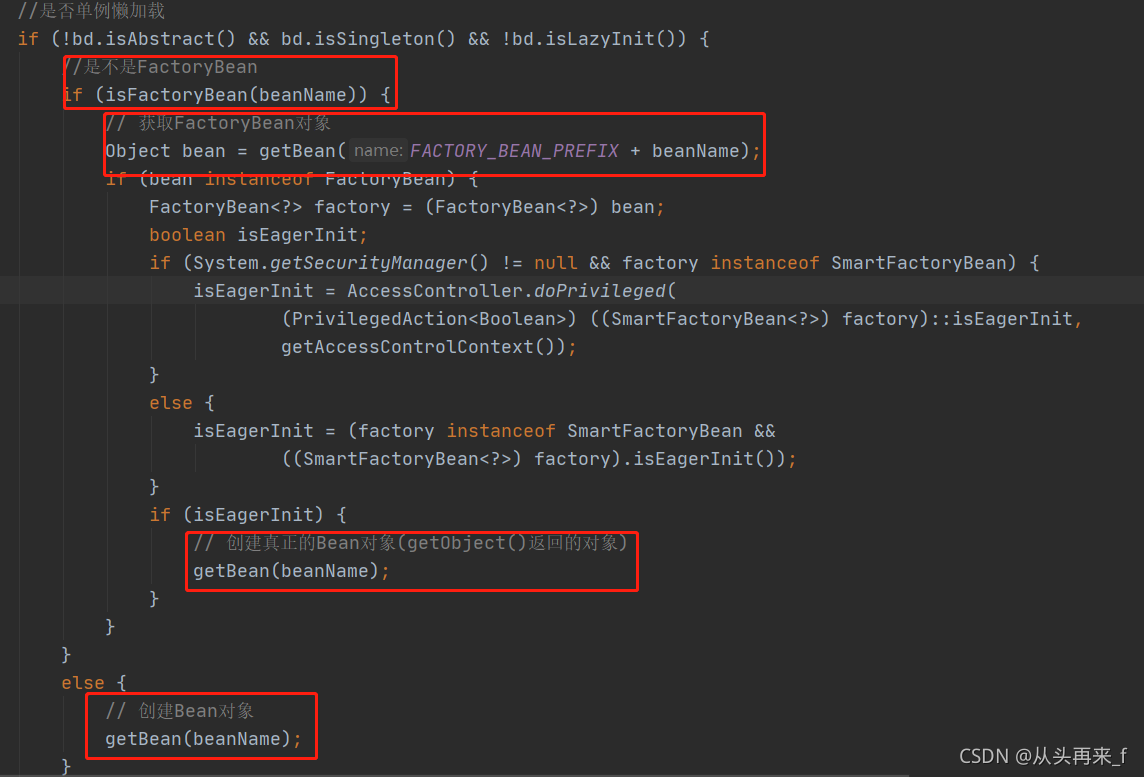
以上代码可以看到首先判断当前beanName所代表的bean是不是FactoryBean,我们看一下他是如何根据beanName判断当前bean是不是FactoryBean的(注意这个时候该beanName对应的bean对象还没有创建出来,只是读取了BeanDefinition)
首先我们要知道**:单例池中fztxFactoryBean存的是原本的FztxFactoryBean对象,而getobject()的对象是存在另外一个map中,而且是在调用getBean之后才存进去的(SmartFactoryBean除外)**
可以看到单例池中fztxFactoryBean存的是原本的FztxFactoryBean对象,而此时factoryBeanObjectCache是没有值

执行context.getBean("fztxFactoryBean");之后:
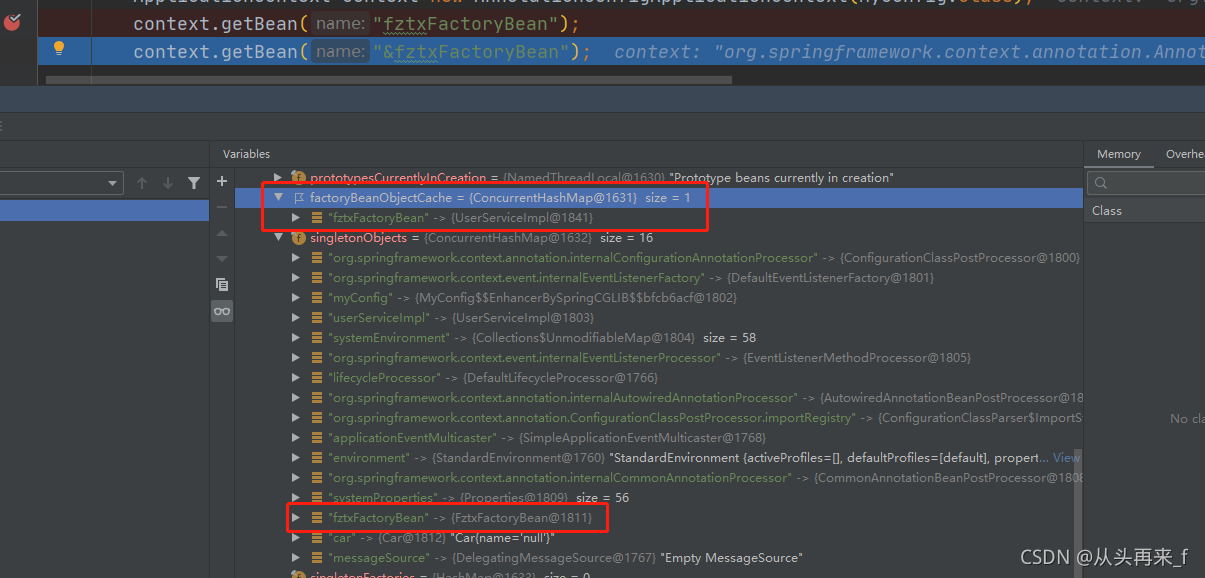
factoryBeanObjectCache存的才是我们要get的bean
我们继续看isFactoryBean方法:
public boolean isFactoryBean(String name) throws NoSuchBeanDefinitionException {
String beanName = transformedBeanName(name);
Object beanInstance = getSingleton(beanName, false);
if (beanInstance != null) {
return (beanInstance instanceof FactoryBean);
}
// No singleton instance found -> check bean definition.
if (!containsBeanDefinition(beanName) && getParentBeanFactory() instanceof ConfigurableBeanFactory) {
// No bean definition found in this factory -> delegate to parent.
return ((ConfigurableBeanFactory) getParentBeanFactory()).isFactoryBean(name);
}
return isFactoryBean(beanName, getMergedLocalBeanDefinition(beanName));
}String beanName = transformedBeanName(name);transformedBeanName(name)方法为beanName转换的执行逻辑,进入该方法会发现,里面还嵌套了多个方法,
protected String transformedBeanName(String name) {
return canonicalName(BeanFactoryUtils.transformedBeanName(name));
}其中BeanFactoryUtils.transformedBeanName(name)方法的功能就是循环去除 FactoryBean的修饰符**(&)**
canonicalName(String name)方法则是从缓存中取指定alias所表示的最终beanName
所以不管是**&fztxFactoryBean** 还是fztxFactoryBean返回的都是fztxFactoryBean
Object beanInstance = getSingleton(beanName, false);从单例池中根据beanName获取bean对象,如果是第一次进入,从单例池拿到的是null,
但是在容器刷新完成之后,取到的就是原本的FactoryBean对象,然后根据bean对象判断是不是FactoryBean

现在是第一次进入,拿到的是null,会继续往下走,首先判断当前beanfactory有没有该beanDefinition,有就继续,没有就调父beanFactory的isFactoryBean,当然最后还是走这个方法

代码继续走:
protected boolean isFactoryBean(String beanName, RootBeanDefinition mbd) {
Boolean result = mbd.isFactoryBean;
if (result == null) {
// 根据BeanDefinition推测Bean类型(获取BeanDefinition的beanClass属性)
Class<?> beanType = predictBeanType(beanName, mbd, FactoryBean.class);
// 判断是不是实现了FactoryBean接口
result = (beanType != null && FactoryBean.class.isAssignableFrom(beanType));
mbd.isFactoryBean = result;
}
return result;
}会根据BeanDefinition推测Bean类型,并且判断是不是实现了FactoryBean接口,将结果缓存起来,实际上断点到这的时候,缓存结果是有值的。
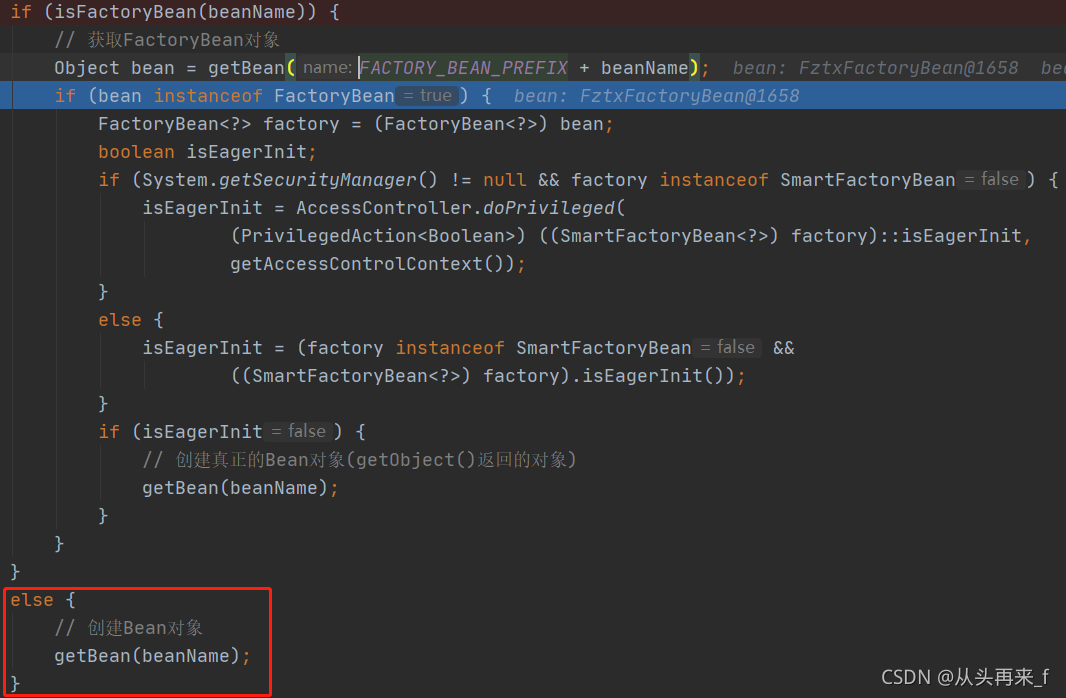
判断如果不是FactoryBean那么就会直接取创建bean对象了
如果是FactoryBean的话,那么先去获取原本的FactoryBean对象,(beanName前加上FactoryBean的修饰符**(&)**)
// 获取FactoryBean对象
Object bean = getBean(FACTORY_BEAN_PREFIX + beanName);这个返回的是FztxFactoryBean,并且存到了单例池中
之后判断是不是实现了SmartFactoryBean,并重写isEagerInit返回true,如果没有实现那么就不会创建我们要获得的bean对象,也就是getObject返回的对象
只有在我们调用context.getBean("fztxFactoryBean")才会去调用getObject
我们可以看到getBean("fztxFactoryBean")拿到的是getObject()返回的对象,而getBean("&fztxFactoryBean")拿到的是原本的FactoryBean,我们看一下spring是如何处理的
我们看一下doGetBean方法:
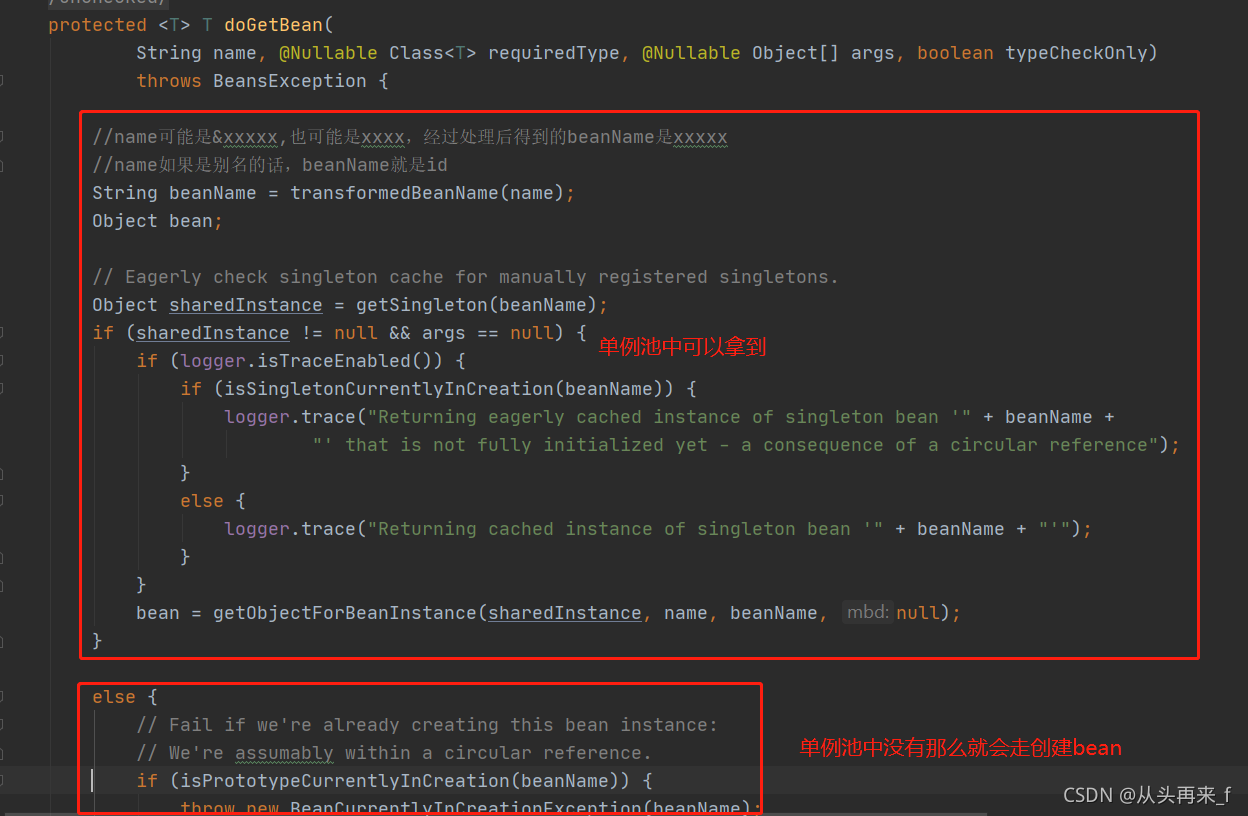
首先又是transformedBeanName(name)方法,根据传进来的name得到一个新beanName
name可能是&xxxxx,也可能是xxxx,经过处理后得到的beanName是xxxxx
然后根据beanName去单例池中取对应bean,(这里只考虑spring容器启动完成之后,取创建bean的代码下面再分析)
代码继续走,

方法参数有:
sharedInstance:单例池中拿到的bean
name:我们原本上送的name
beanName:转换之后的beanname
BeanDefinition:null
首先判断我们原本上送的name是不是以FactoryBean的修饰符**(&)**开始,如果是说明我们想得到的就是原本的FactoryBean,而我们从单例池中拿到的就是原本的FactoryBean,直接返回
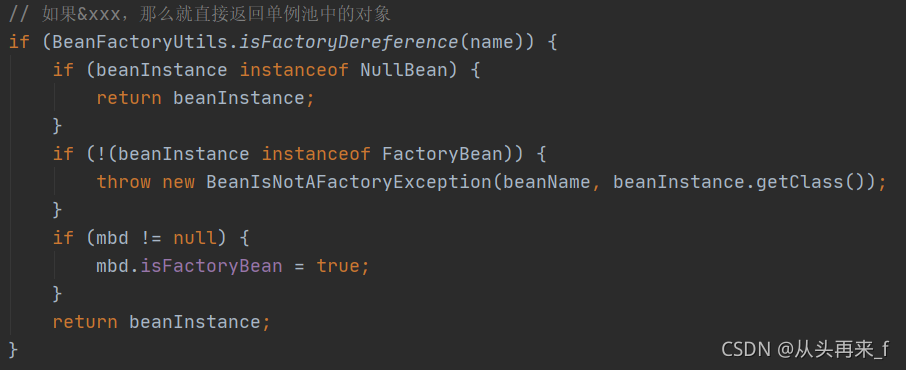
如果name不是以FactoryBean的修饰符**(&)**开始,两种情况:
判断单例池中拿到的bean是不是FactoryBean,如果不是FactoryBean,说明就是一个普通bean,直接返回
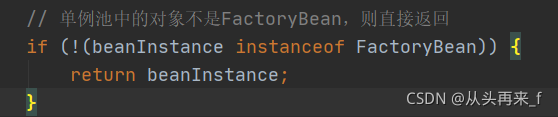
如果是FactoryBean,我们就应该要去getObject
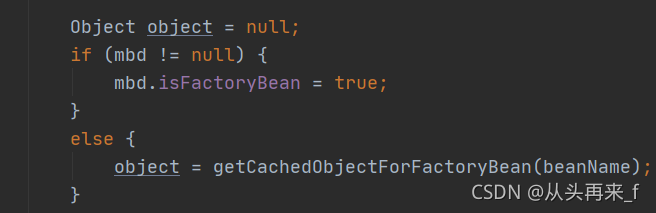
上面传的参数 mbd是null,所以走getCachedObjectForFactoryBean方法:
protected Object getCachedObjectForFactoryBean(String beanName) {
return this.factoryBeanObjectCache.get(beanName);
}先去factoryBeanObjectCache中去取,就是上面说的存FactoryBean.getObject()对象的map;
取不到再去调用getObject()

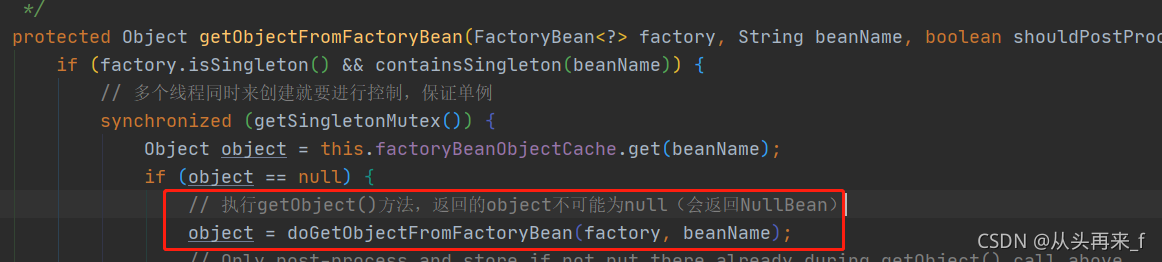
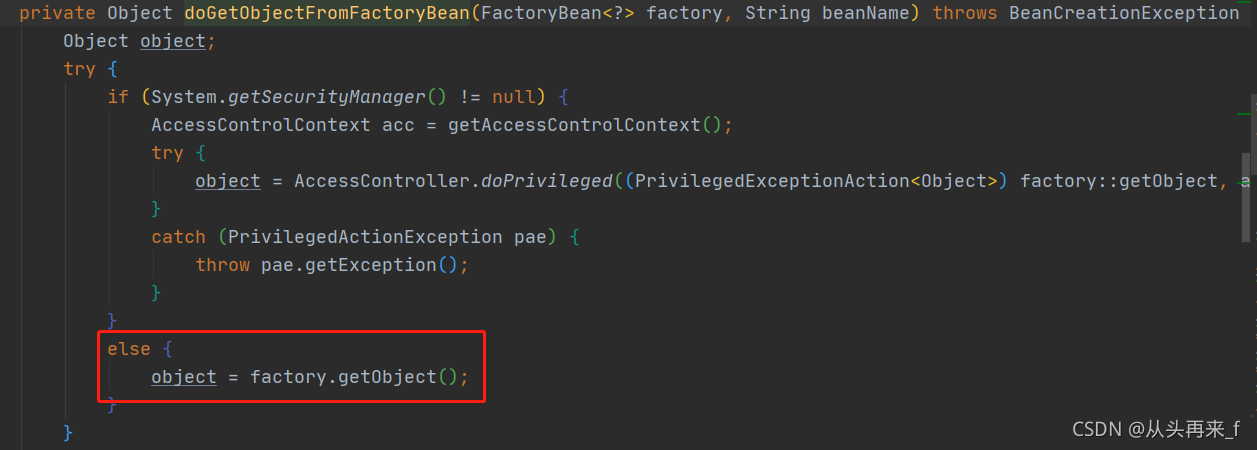
这样返回的就是getObject()返回的bean了。
上面是spring容器启动之后,可以从单例池中获取到单例bean的情况,而在spring容器首次启动时或者时原型bean的情况下时获取不到的,那么就会去创建bean,就是根据beanDefinition-->spring bean的过程 ,这部分就是bean的生命周期的主要部分,会在下一篇文章分析。
我们先看创建完之后的一段代码,循环创建完所有的非懒加载单例bean之后,spring又循环了一次beanName
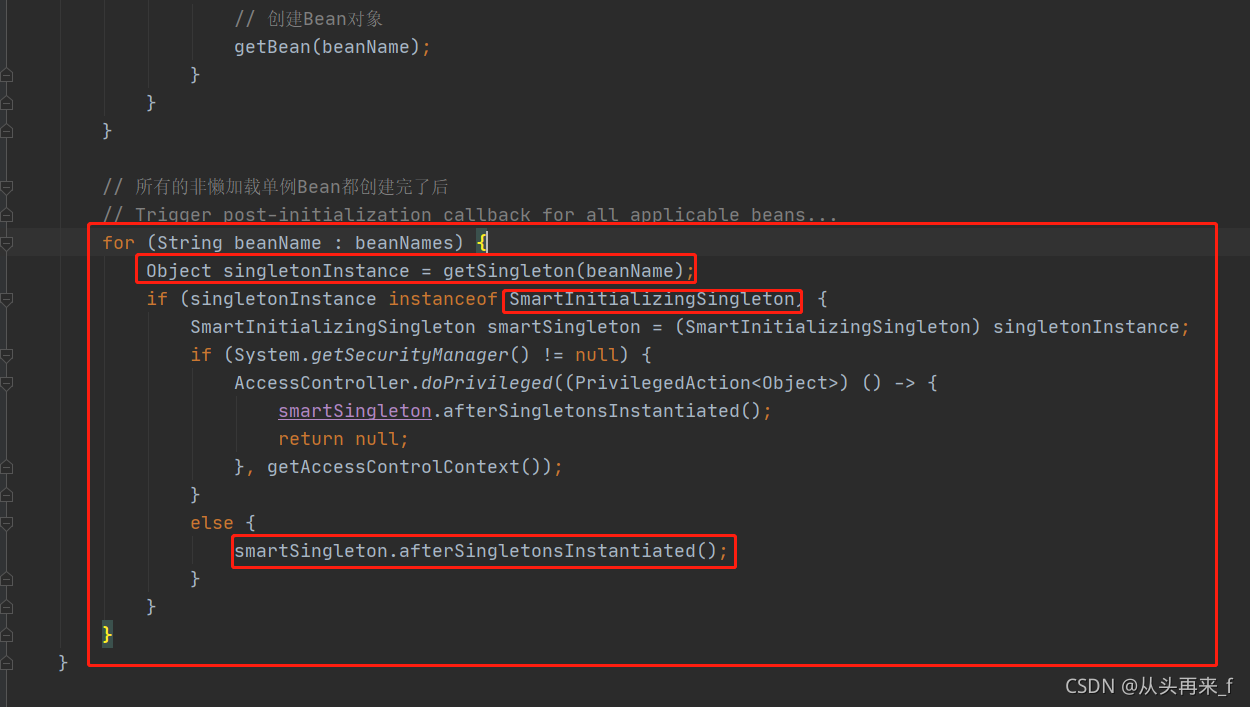
首先从单例池中拿到bean对象,判断该bean是否实现了SmartInitializingSingleton接口,如果实现了,就会执行afterSingletonsInstantiated方法,注意,这个方法是在所有非懒加载单例bean之后才会执行,不同于初始化前,初始化后执行的方法,那些是在单个bean创建过程中执行的。