1、Elasticsearch 基础命令
1、Elasticsearch 基础命令
1.1基础概念
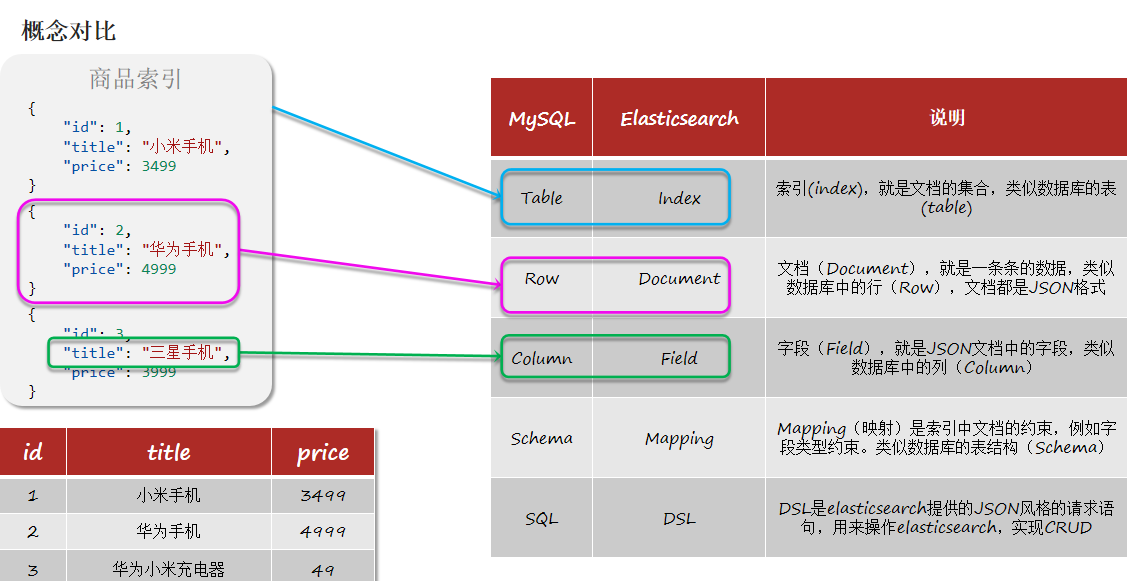
1.2 分词器
es在创建倒排索引时需要对文档分词;在搜索时,需要对用户输入内容分词。但默认的分词规则对中文处理并不友好。我们在kibana的DevTools中测试:
POST /_analyze
{
"analyzer": "standard",
“text”: “黑马程序员学习java非常棒!"
}语法说明:
- POST:请求方式/_analyze:
- 请求路径,这里省略了http://192.168.150.101:9200,有kibana帮我们补充请求参数,
- json风格:analyzer:
- 分词器类型,这里是默认的standard分词器
- text:要分词的内容
1. ik分词器-拓展词库
要拓展ik分词器的词库,只需要修改一个ik分词器目录中的config目录中的IkAnalyzer.cfg.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 *** 添加扩展词典-->
<entry key="ext_dict">ext.dic</entry>
</properties>然后在名为ext.dic的文件中,添加想要拓展的词语即可:
鸡你太美
奥力给2. ik分词器-停用词库
要禁用某些敏感词条,只需要修改一个ik分词器目录中的config目录中的IkAnalyzer.cfg.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典-->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典 *** 添加停用词词典-->
<entry key="ext_stopwords">stopword.dic</entry>
</properties>然后在名为stopword.dic的文件中,添加想要拓展的词语即可:
你妈的
死妈的
卧槽1.3 索引库操作
1. mapping属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
type:字段数据类型,常见的简单类型有:
字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
数值:long、integer、short、byte、double、float
布尔:boolean
日期:date
对象:object
index:是否创建索引,默认为true
analyzer:使用哪种分词器properties:该字段的子字段
properties:该字段的子字段
2. 创建索引库
ES中通过Restful请求操作索引库、文档。请求内容用DSL语句来表示。创建索引库和mapping的DSL语法如下:
PUT /索引库名称
{
"mappings": {
"properties": {
"字段名":{
"type": "text",
"analyzer": "ik_smart"
},
"字段名2":{
"type": "keyword",
"index": "false"
},
"字段名3":{
"properties": {
"子字段": {
"type": "keyword"
}
}
},
// ...略
}
}
}3. 查看、删除索引库
查看索引库语法:
GET /索引库名
示例:
GET /heima删除索引库的语法:
DELETE /索引库名
示例:
DELETE /heima4. 修改索引库
索引库和mapping一旦创建无法修改,但是可以添加新的字段,语法如下:
PUT /索引库名/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}
示例:
PUT /heima/_mapping
{
"properties": {
"age":{
"type": "integer"
}
}
}1.4 文档操作
1. 添加文档
新增文档的DSL语法如下:
POST /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
// ...
}
示例:
POST /heima/_doc/1
{
"info": "黑马程序员Java讲师",
"email": "zy@itcast.cn",
"name": {
"firstName": "云",
"lastName": "赵"
}
}2. 查看、删除文档
查看文档语法:
GET /索引库名/_doc/文档id
示例:
GET /heima/_doc/1删除索引库的语法:
DELETE /索引库名/_doc/文档id
示例:
DELETE /heima/_doc/13. 修改文档
方式一:全量修改,会删除旧文档,添加新文档
PUT /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}
示例:
PUT /heima/_doc/1
{
"info": "黑马程序员高级Java讲师",
"email": "zy@itcast.cn",
"name": {
"firstName": "云",
"lastName": "赵"
}
}方式二:增量修改,修改指定字段值
POST /索引库名/_update/文档id
{
"doc": {
"字段名": "新的值",
}
}
示例:
POST /heima/_update/1
{
"doc": {
"email": "ZhaoYun@itcast.cn"
}
}1.5 操作集合
GET _search
{
"query": {
"match_all": {}
}
}
#ik_smart 最少切分
GET /_analyze
{
"analyzer": "ik_smart",
"text": "黑马程序员,尼玛,你妈的,死了啊,你妈的"
}
#ik_max_word 最细切分
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "传智播客Java就业超过90%,奥力给!"
}
#创建索引库
PUT /heima
{
"mappings": {
"properties":{
"info":{
"type":"text",
"analyzer":"ik_smart"
},
"email":{
"type":"keyword",
"index":false
},
"name":{
"properties":{
"firstName":{
"type":"keyword"
},
"lastName":{
"type":"keyword"
}
}
}
}
}
}
#查询索引库
GET /heima
#删除索引库
DELETE /heima
#修改索引库 (库内容无法修改,但是可以添加新的字段)
PUT /heima/_mapping
{
"properties":{
"age":{
"type":"integer"
}
}
}
#新增文档
POST /heima/_doc/1
{
"info":"黑马陈煦园",
"email":"zy@qq.com",
"name":{
"firstName":"云",
"lastName":"赵"
}
}
#查询文档语法
GET /heima/_doc/1
#删除文档
DELETE /heima/_doc/1
#修改文档(全量修改 删除旧的 增加新的)
PUT /heima/_doc/1
{
"info":"黑马陈煦园",
"email":"zy@qq.com",
"name":{
"firstName":"汉聪",
"lastName":"刘"
}
}
#修改文档(增量修改 修改指定的字段)
POST /heima/_update/1
{
"doc":{
"info":"黑马程序员",
"age":18
}
}